Haf API Node Setup
Craddle to Grave guide to setup a haf_api_node (still in development).
Initial Server Setup
Just getting yourself a server with 4TB of nvme diskspace isn't quite enough. You will likely need to disable any software RAID to actually have 4TB of space. The following are steps to use a rescue image and Hetzner's Install OS to bring your system online. These steps will be similar with other providers or even running the system from an ubuntu setup disk.
Hardware Requirements
- 32GB RAM
- 4TB NVME (additional SSD or HD is great too)
- Ubuntu 22.04 or better (23.10 preferred)
Let's Go
ssh into your server
Let's look at lsblk
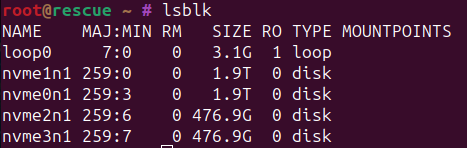
You should see some disks here, note if you have some SSDs and some NVMEs you can install your OS on the SSD(or even SATA HD) and leave the NVMEs just for haf.
installimage - Hetzner OS install
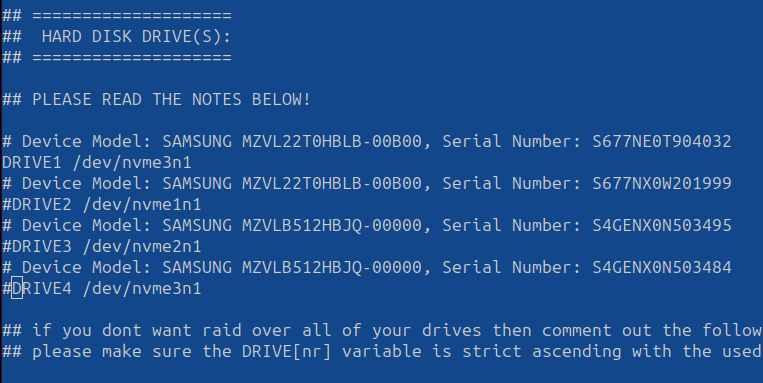
Here you will comment out any NVME Drives you want to use for haf, and make DRIVE1 your HD/SSD/NVME of choice.
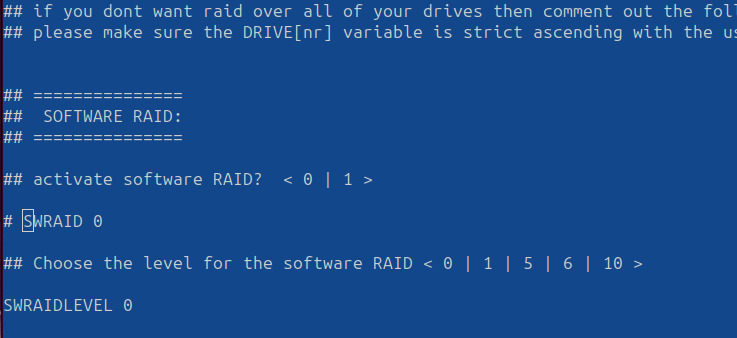
Ensure to disable (#) your Software RAID (SWRAID) and select 0 or 1 in the SWRAIDLEVEL
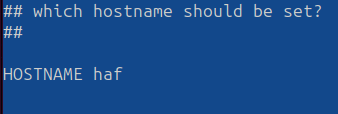
Why not make your hostname smaller like haf or haf2 because jammy-2204-blah-blah-blah gets annoying to look at and doesn't tell you much if you have many boxes in the wild.
- Save [F2] and exit [F10]
- F10 might require you to push [Esc] first
reboot
Next time you ssh into your system you'll have a new fingerprint as the OS has changed.
First things first. Let's make sure your drives are set up correctly
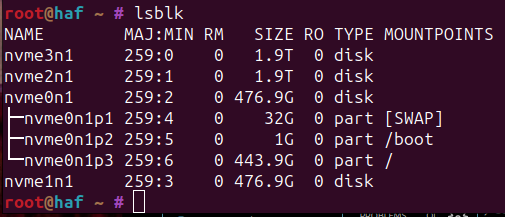
Hopefully you'll see at least 4TB of nvme disk(s) with no mountpoints.
Housekeeping:
sudo apt update && sudo apt upgrade -y
If you are going to upgrade to 23.10 now is the best time.
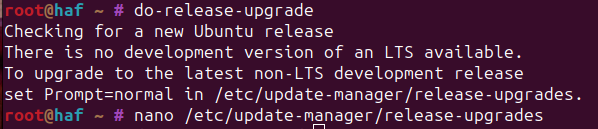
sudo nano /etc/update-manager/release-upgrades- Change
ltstonormaland save - If you use the 'do-release-upgrade -d` with the -d flag at this point in time you'll find yourself in a 24.04-dev system which doesn't have an official docker release. Docker does seem to be working with the 23.10 version, and I haven't found any other issues, but I'm not going to cover that install path here.
- Change
sudo do-release-upgrade-> 23.04- Follow the instructions... then do it again
sudo do-release-upgrade-> 23.10
We haven't even got to the haf install and it's nearly over! Let's move into the real meat of the operation.
git clone https://gitlab.syncad.com/hive/haf_api_node.gitcd haf_api_node/
You really should read the README... But if you want to get going as quick as possible let's get it going:
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin zfsutils-linux -y
Copy and paste the above to get the prerequisites installed: docker and zfs utilities.
Then run ./assisted_starup.sh
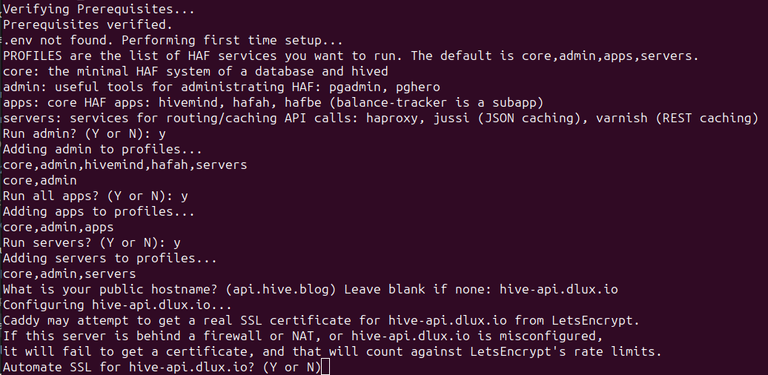
This script will:
- verify your prerequists
- build an environment file
.env(as needed)- Ask which services you intend to run
- Ask what domain name you have set up
- Ask if you wish to have your SSL certificates managed
- (Please have your DNS properly configured by this point if you say yes)
- Scan for unmounted NVME drives (as needed)
- Build a ZFS pool with those drives (as needed)
- Create haf datasets in the zpool (as needed)
- Build a RAM Disk to significantly speed up syncing times (disable with --no-ramdisk)
- Start the Sync with only Core and Admin profiles
- Monitor memory usage durring the Sync and add swapfiles (disable with --no-autoswap) to prevent OOM
- Upon initial Sync:
- Will take a snapshot named "first_sync" so any changes made can forgo the long replay.
- Unmount the RAM Disk to improve API performance
- Add any additional services to be run (servers, apps, hafah...)
- Move memory management and sync times to a haf.log file
- Also remove any "--replay" arguments
That's it. In 2(core)-7(with all apps) days you should have a fully synced haf_api_node at your.domain.com
Efforts
@blocktrades and company have put a lot of work into this to make spinning up new API nodes really easy. The continued progress of the years with snapshots, data compression, docker deploys, haf in general... really shine a light on how far and professional the system has gotten. I believe my node now is smaller than it was a couple of years ago, and for sure syncs faster even with a blockchain about twice the size, which keeps the costs down and improves our ability to have a well functioning ecosystem.
I did write the assisted_startup.sh script that helps get things moving... as manually finding certain information is error prone, and monitoring the system yourself is not fun. That said, every step in the README can be done and still take advantage of the memory management features of the script.
One of the biggest reasons to do that would be to run additional or fewer plugins on the hived config.ini... as these plugins need to be ran from the beginning. Other reasons might be to make your zpool from a mix of SSDs or to not include all available NVMEs in the pool. So certainly take a look at the README if you plan on doing anything non-standard.
Running API nodes isn't exactly cheap, and I have 2 of them now. If you'd like to support my witness I'd be forever thankful.
Public API Specs
hive-api.dlux.io
Testing across:
Ryzen 5 / 64GB / 5TB NVMEs / Germany => Ubuntu 23.10
Ryzen 9 / 64GB / 4TB NVMEs / 2TB HHD / Germany => Ubuntu 24.04-dev
The Hive.Pizza team manually curated this post.
Learn more at https://hive.pizza.
Thank you for this. I'm working on getting a node up. Just switched to Fiber Optics today and either tomorrow or probably Wednesday I will buy the hardware.
I understand we need a big fast NVME and RAM, but what about processor? Any input?
I've personally had fine results on Ryzen 5 and Ryzen 9... I after the replay it's not a very intensive process, so it depends more on how much traffic you intend to handle.
How do I know how much traffic I want to handle?
Edit: I think I answered my question. Depends on the apps and users.
I'd need to phone a friend for this question...

I’m not a person who is mostly interested in nodes but thank you for this lecture
It is useful and I was able to learn from it
Thank you for this detail knowledge and I must say I am really learning a lot reading this today. Thank you so much for sharing this
Congratulations @disregardfiat! You received a personal badge!
Wait until the end of Power Up Day to find out the size of your Power-Bee.
May the Hive Power be with you!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
Congratulations @disregardfiat! You received a personal badge!
See you at the next Power Up day to see if you will repeat this feat.
May the Hive Power be with you!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
Hello disregardfiat!
It's nice to let you know that your article won 🥇 place.
Your post is among the best articles voted 7 days ago by the @hive-lu | King Lucoin Curator by hallmann
You and your curator receive 0.1695 Lu (Lucoin) investment token and a 9.45% share of the reward from Daily Report 194. Additionally, you can also receive a unique LUGOLD token for taking 1st place. All you need to do is reblog this report of the day with your winnings.
Buy Lu on the Hive-Engine exchange | World of Lu created by @szejq
STOPor to resume write a wordSTARTThat's basically what I tend to perform as basic updates for my ubuntu server, I am thinking to switch over to ZFS, those snapshots make nice and fast to restore.
Can I ask you for a witness vote please. I am running my witness node on my private server, hosted here in Adelaide. it would be great to have your support.